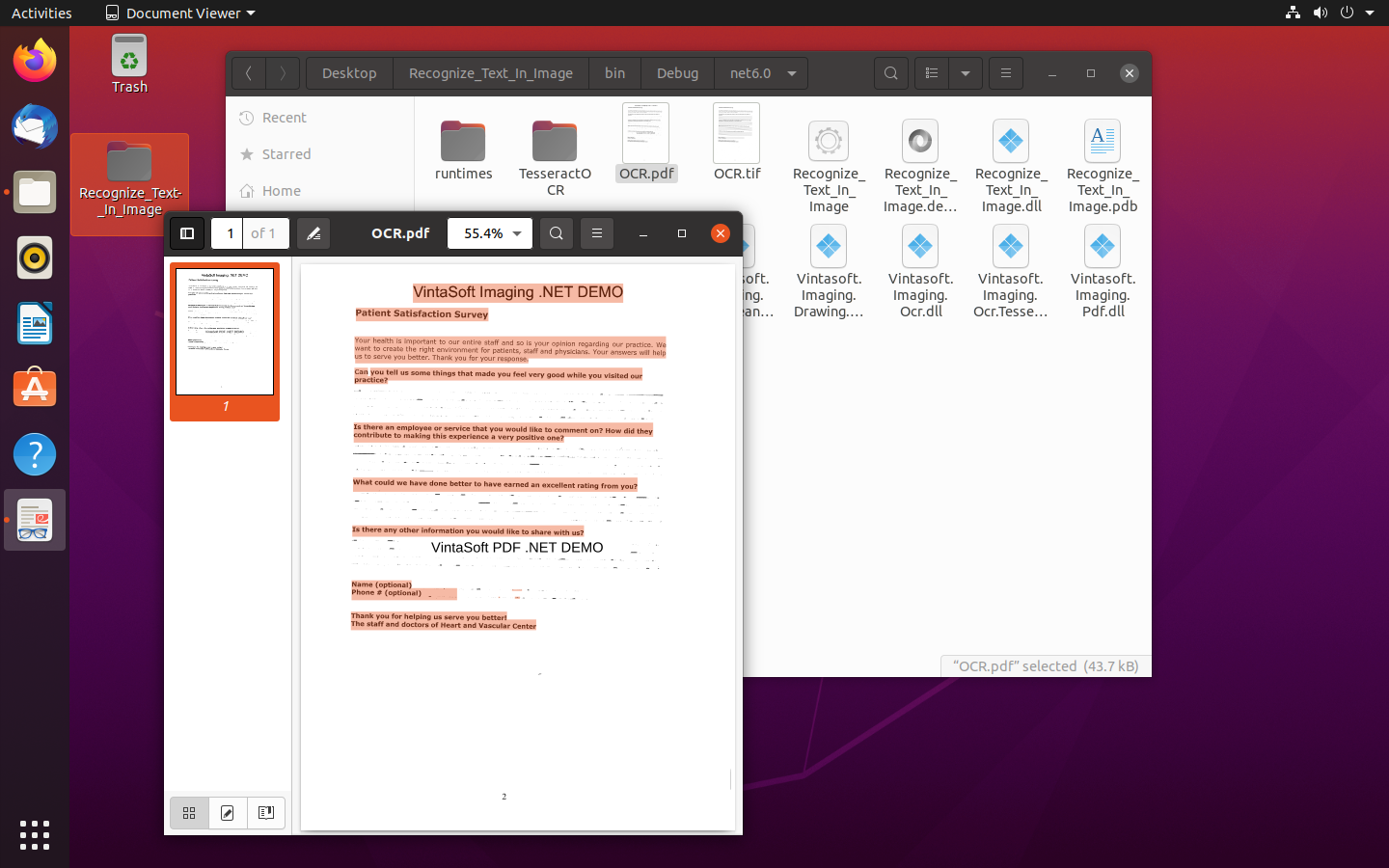
Recognize text in image using a .NET application for Linux
Blog category: Imaging; OCR; .NET; Linux
December 23, 2022
dotnet new console --framework net6.0
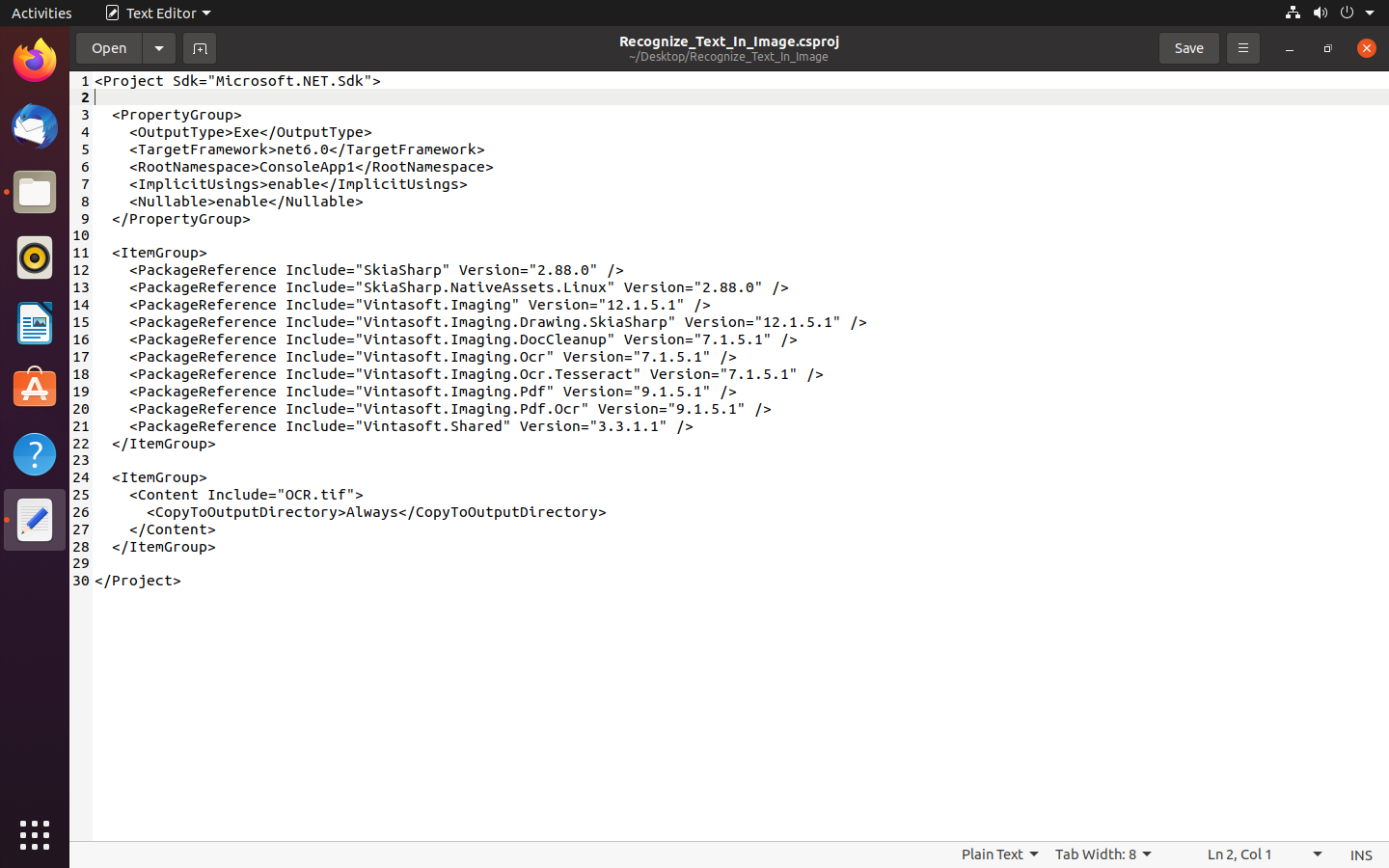
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net6.0</TargetFramework>
<RootNamespace>ConsoleApp1</RootNamespace>
<ImplicitUsings>enable</ImplicitUsings>
<Nullable>enable</Nullable>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="SkiaSharp" Version="2.88.0" />
<PackageReference Include="SkiaSharp.NativeAssets.Linux" Version="2.88.0" />
<PackageReference Include="Vintasoft.Imaging" Version="12.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.Drawing.SkiaSharp" Version="12.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.DocCleanup" Version="7.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.Ocr" Version="7.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.Ocr.Tesseract" Version="7.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.Pdf" Version="9.1.5.1" />
<PackageReference Include="Vintasoft.Imaging.Pdf.Ocr" Version="9.1.5.1" />
<PackageReference Include="Vintasoft.Shared" Version="3.3.1.1" />
</ItemGroup>
<ItemGroup>
<Content Include="OCR.tif">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
</Content>
</ItemGroup>
</Project>
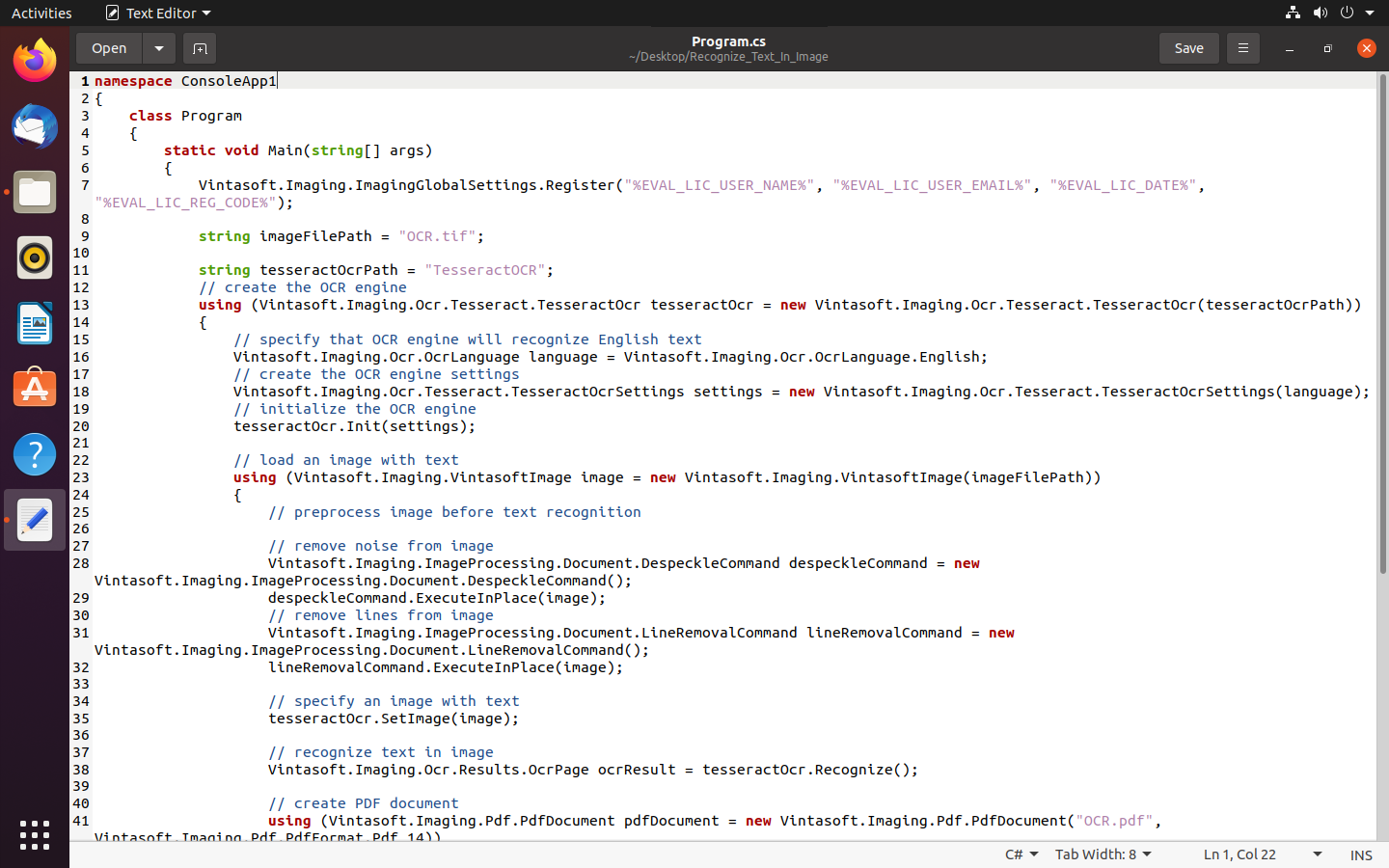
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
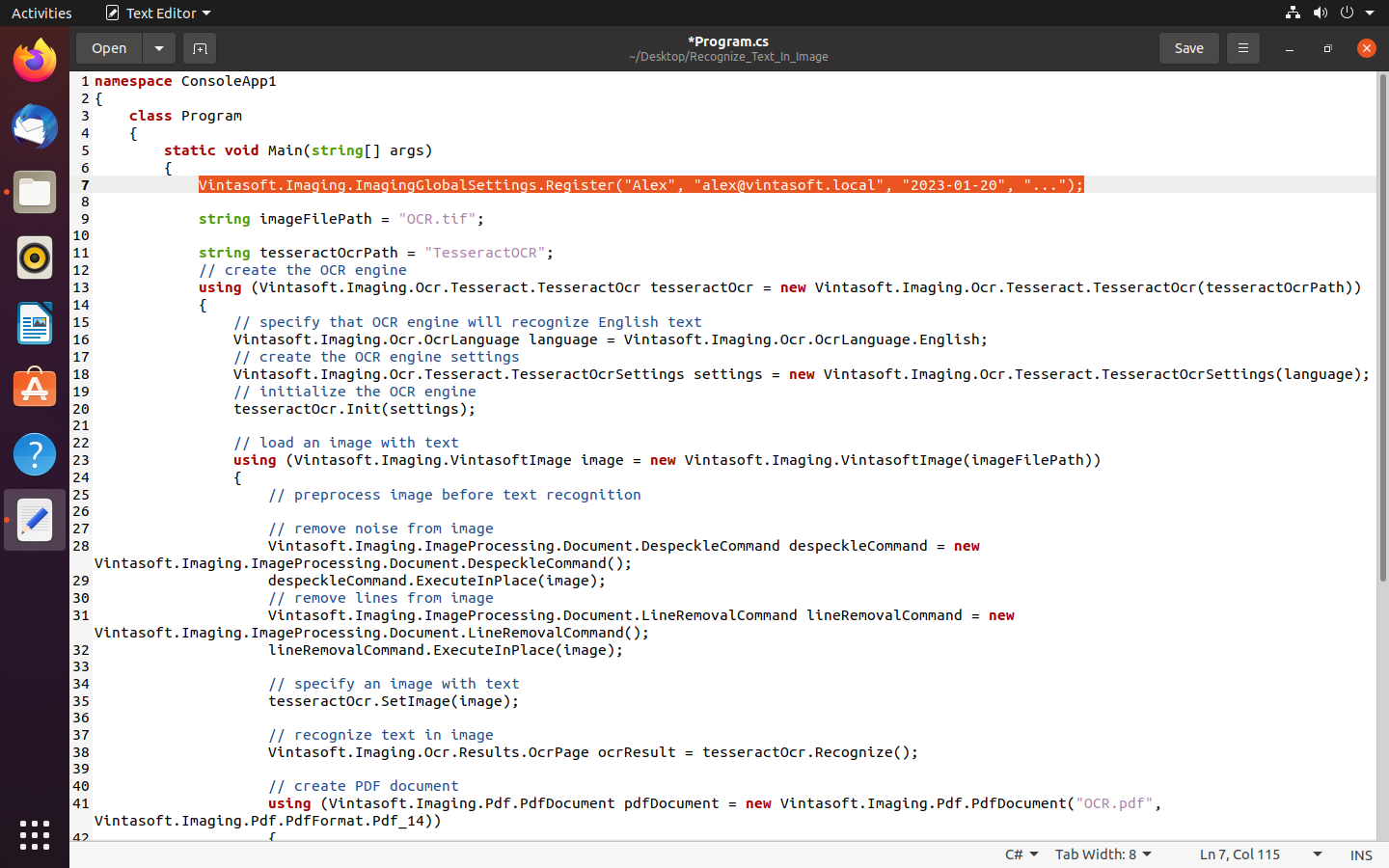
Vintasoft.Imaging.ImagingGlobalSettings.Register("%EVAL_LIC_USER_NAME%", "%EVAL_LIC_USER_EMAIL%", "%EVAL_LIC_DATE%", "%EVAL_LIC_REG_CODE%");
string imageFilePath = "OCR.tif";
string tesseractOcrPath = "TesseractOCR";
// create the OCR engine
using (Vintasoft.Imaging.Ocr.Tesseract.TesseractOcr tesseractOcr = new Vintasoft.Imaging.Ocr.Tesseract.TesseractOcr(tesseractOcrPath))
{
// specify that OCR engine will recognize English text
Vintasoft.Imaging.Ocr.OcrLanguage language = Vintasoft.Imaging.Ocr.OcrLanguage.English;
// create the OCR engine settings
Vintasoft.Imaging.Ocr.Tesseract.TesseractOcrSettings settings = new Vintasoft.Imaging.Ocr.Tesseract.TesseractOcrSettings(language);
// initialize the OCR engine
tesseractOcr.Init(settings);
// load an image with text
using (Vintasoft.Imaging.VintasoftImage image = new Vintasoft.Imaging.VintasoftImage(imageFilePath))
{
// preprocess image before text recognition
// remove noise from image
Vintasoft.Imaging.ImageProcessing.Document.DespeckleCommand despeckleCommand = new Vintasoft.Imaging.ImageProcessing.Document.DespeckleCommand();
despeckleCommand.ExecuteInPlace(image);
// remove lines from image
Vintasoft.Imaging.ImageProcessing.Document.LineRemovalCommand lineRemovalCommand = new Vintasoft.Imaging.ImageProcessing.Document.LineRemovalCommand();
lineRemovalCommand.ExecuteInPlace(image);
// specify an image with text
tesseractOcr.SetImage(image);
// recognize text in image
Vintasoft.Imaging.Ocr.Results.OcrPage ocrResult = tesseractOcr.Recognize();
// create PDF document
using (Vintasoft.Imaging.Pdf.PdfDocument pdfDocument = new Vintasoft.Imaging.Pdf.PdfDocument("OCR.pdf", Vintasoft.Imaging.Pdf.PdfFormat.Pdf_14))
{
// create PDF document builder
Vintasoft.Imaging.Pdf.Ocr.PdfDocumentBuilder documentBuilder = new Vintasoft.Imaging.Pdf.Ocr.PdfDocumentBuilder(pdfDocument);
documentBuilder.ImageCompression = Vintasoft.Imaging.Pdf.PdfCompression.Auto;
documentBuilder.PageCreationMode = Vintasoft.Imaging.Pdf.Ocr.PdfPageCreationMode.ImageOverText;
// add OCR result to the PDF document
documentBuilder.AddPage(image, ocrResult);
// save changes in PDF document
pdfDocument.SaveChanges();
}
// clear the image
tesseractOcr.ClearImage();
}
// shutdown the OCR engine
tesseractOcr.Shutdown();
}
}
}
}
dotnet build Recognize_Text_In_Image.csproj
dotnet ./Recognize_Text_In_Image.dll